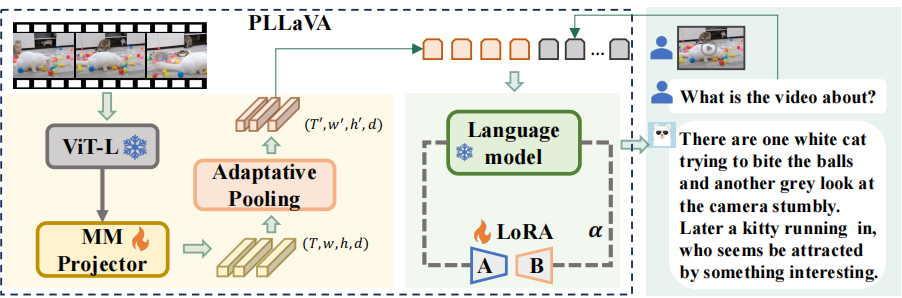
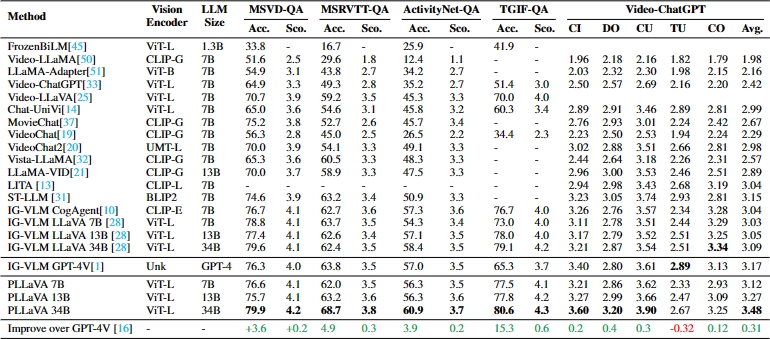
PLLaVA: Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
A video assistant.
With imagenary captioning ability.
See our PLLAVA in the Pool →
7b Gradio 13b Gradio 34b Gradio